Retrospective: What have we accomplished with DNA sequencing so far?
Sanger wasn’t the first person to attempt sequencing, but before his classic method was invented, the process was painfully slow and cumbersome. Before Sanger, Gilbert and Maxam sequenced 24 bases of the lactose-repressor binding site by copying it into RNA and sequencing the RNA–which took a total of 2 years [1]!
Sanger’s process sequencing made the process much more efficient. Original Sanger sequencing took a ‘sequencing by synthesis’ approach, creating 4 extension reactions, each with a different radioactive chain-terminating nucleotide to identify what base lay at each position along a DNA fragment. When he ran each of those reactions out on a gel, it became relatively simple to identify the sequence of the DNA fragment (see Figure 1) [2].

Of course, refinements have been made to the process since then. We now label each of the nucleotides with a different fluorescent dye, which allows for the same process to occur but using only one extension reaction instead of 4, greatly simplifying the protocol. Sanger received his second Nobel Prize for this discovering in 1980 (well-deserved, considering it is still used today).
An early version of the Human Genome Project (HGP) began not long after this discovery in 1987. The project was created by the United States Department of Energy, which was interested in obtaining a better understanding of the human genome and how to protect it from the effects of radiation. A more formalized version of this project was approved by Congress in 1988 and a five-year plan was submitted in 1990 [3]. The basic overview of the protocol for the HGP emerged as follows: the large DNA fragments were cloned in bacterial artificial chromosomes (BACs), which were then fragmented, size-selected, and sub-cloned. The purified DNA was then used for Sanger sequencing, and individual reads were then assembled based on overlaps between the reads.
Given how large the human genome is, and the limitations of Sanger sequencing, it quickly became apparent that more efficient and better technologies were necessary, and indeed, a significant part of the HGP was dedicated to creating these technologies. Several advancements in both wet-lab protocol and data analysis pipelines were made during this time, including the advent of paired-end sequencing and the automation of quality metrics for base calls.
Due to the relatively short length of the reads produced, the highly repetitive parts of the human genome (such as centromeres, telomeres and other areas of heterochromatin) remained intractable to this sequencing method. Despite this, a draft of the HGP was submitted in 2001, with a finished sequence submitted in 2004–all for the low, low cost $2.7 billion.
Since then, there have been many advancements to the process of DNA sequencing, but the most important of these is called multiplexing. Multiplexing involves tagging different samples with a specific DNA barcode, which allows us to sequence multiple samples in one reaction tube, vastly increasing the amount of data we can obtain per sequencing run. Interestingly, the most frequently used next-generation sequencing method today (the Illumina platforms–check them out here) still uses the basics of Sanger sequencing (i.e., detection of fluorescently labelled nucleotides), combined with multiplexing and a process called bridge amplification to sequence hundreds of millions of reads per run.
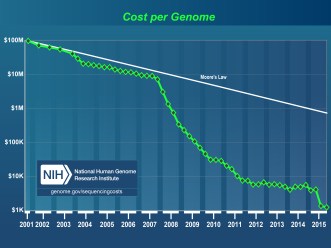
Rapid advancement in genome sequencing since 2001 have greatly decreased the cost of sequencing, as you can see in Figure 2 [4]. We are quickly approaching sequencing of the human genome for less than $1,000–which you can see here on our website.
What are we doing with sequencing today?
Since the creation of next-generation DNA sequencing, scientists have continued to utilize this technology in increasingly complex and exciting new ways. RNA-sequencing, which involves isolating the RNA from an organism, converting it into cDNA, and then sequencing resulting cDNA, was invented shortly after the advent of next-generation sequencing and has since become a staple of the molecular biology and genetics fields. ChIP-seq, Ribo-Seq, RIP-seq, and methyl-seq followed and have all become standard experimental protocols as well. In fact, as expertly put by Shendure et al. (2017), ‘DNA sequencers are increasingly to the molecular biologist what a microscope is to the cellular biologist–a basic and essential tool for making measurements. In the long run, this may prove to be the greatest impact of DNA sequencing.’ [5] In my own experience, utilizing these methods in ways that complement each other (like cross-referencing ChIP-seq or Ribo-Seq data with RNA-seq data) can produce some of the most exciting scientific discoveries.

Although Illumina sequencing still reigns supreme on the market, there are some up and coming competitor products as well. Of great interest is the MinION from Oxford Nanopore Technologies (ONT) (see more about them here). MinION offers a new type of sequencing that offers something the Illumina platforms lack–the ability to sequence long regions of DNA, which is of enormous value when sequencing through highly repetitive regions. MinION works via a process called nanopore sequencing, a system which applies voltage across hundreds of small protein pores. At the top of these pores sits an enzyme that processively unwinds DNA down through the pore, causing a disruption in the voltage flow which can measured at the nucleotide level (see Figure 3) [6]. These reads can span thousands of base pairs, orders of magnitude greater than the Illumina platforms, which greatly simplifies genome assembly. Other new options for long-read sequencing include the PacBio system from Pacific Biosciences (look for pricing options for this service here).
Like any new technology, there have been setbacks. The early accuracy of MinION cells was quite low compared with Illumina, and the output was quite low as well. And although these issues have mainly been addressed, MinION still trails in the market compared to Illumina platforms, which are seen as more reliable and well-characterized. However, MinION has several advantages that could eventually lead to it being more commonly used in the future: for one, it literally fits in the palm of your hand, making it much more feasible for people like infectious diseases researchers, who are in desperate need of sequencing capabilities in remote locales. It’s fast as well; in one example, a researcher in Australia was able to identify antibiotic resistance genes in cultured bacteria in 10 hours [7]–an absolutely incredible feat that couldn’t have been imagined until very recently. This kind of technology could easily be used in hospitals to assist in identifying appropriate patient treatments, hopefully within a few years.
Although we are not regularly able to utilize sequencing technology for medical treatments as of yet, there are a few areas where this is currently happening. Detecting Down’s syndrome in a fetus during pregnancy used to be a much more invasive process, but with improvements in sequencing technology, new screens have been invented that allow for the detection of chromosomal abnormalities circulating in the maternal blood [8]. Millions of women have already benefitted from this improved screen.
Perspective: What does the future of DNA sequencing hold?
As the Chinese poet Lao Tzu said, ‘Those who have knowledge, don’t predict’, and that’s as true as ever when it comes to DNA sequencing technology. We’re capable today of things we couldn’t even have dreamed of 40 years ago, so who knows where we’ll be in the next 40 years?
But as a scientist, I’ve always enjoyed making educated guesses, so here’s some limited predictions about what the future might hold.
Clinical applications: I’ve never been a fan of the term personalized medicine, since it implies that one day doctors will be able to design individual treatments for each patient’s specific illness. I find this scenario unlikely (at least in the near future), because even though the cost and time of DNA sequencing has decreased by astonishing amounts, it still is expensive and time-consuming enough that it doesn’t seem likely to be of great use for clinical applications (to say nothing of cost and time for developing new drug regiments). However, I have high hopes for the future of precision medicine, particularly in cancer treatments. Although we may never be able to design the perfect drug specifically designed to target one individual’s cancer, we can certainly create drugs that are designed to interact with the frequently observed mutations we see in cancers. This could allow for a more individualized drug regiment for patients. Given that cancer is a disease with such extremely wide variations, we will almost certainly need to start taking more targeted approach to its treatment, and genome sequencing will be of great benefit to us in this regard.
A fully complete human genome: As I mentioned previously, one drawback of Illumina sequencing is that it is not capable of sequencing across highly repetitive regions, and unfortunately, large swaths of the human genome are highly repetitive. As such, while we have what is very close to a complete human genome, we do not have the full telomere-to-telomere sequence down as of yet. However, with the new long-read technologies that are currently being implemented, the day when this will be completed is likely not far off.
A complete tapestry of human genetic variation: Millions of people have already had their genomes sequenced to some degree (I’m one of them! Any others?), and millions more are sure to come. Widespread genome re-sequencing could one day allow us to have a full catalog of virtually every heterozygous gene variant in the world, which could allow for an even greater understanding of the connection between our genetics and specific traits.
Faster and better data analysis: Data analysis is probably the biggest bottleneck we’re currently experience when it comes to DNA sequencing. There is what seems like an infinite amount of data out there and unfortunately, a finite number of people who are capable of and interested in analyzing it. As these technologies become more and more mature and established, new and better data analysis pipelines will eventually be created, speeding up analysis time and increasing our understanding the data. Hopefully, one day even scientists with only moderate technical savvy will be capable of performing their own data analysis.
I’m certain the future of DNA sequencing will also hold things that I can’t even imagine. It’s an amazing time to be a scientist right now, as researchers are continuously discovering new technologies, and finding ways to put our current technologies to even more interesting uses.
What do you think the next big thing in DNA sequencing will be? Tell us in the comments!

Leave a comment